Engineering Radiology AI for National Scale in the US
vRad, a large US teleradiology practice and Qure.ai have been colloborating for more than an year for a large scale radiology AI deployment. In this blog post, we describe the engineering that goes into scaling radiology AI. We discuss adapting AI for extreme data diversity, DICOM protocol and software engineering.
vRad and Qure.ai have been collaborating on a large-scale prospective validation of qER, Qure.ai’s ICH model for detecting intracranial hemorrhages (ICH) for more than a year. vRad is a large teleradiology practice – 500+ radiologists serving over 2,000 facilities in the United States – representing patients from nearly all states. vRad uses an in-house built RIS and PACS that processes over 1 million studies a month, with the majority of those studies being XR or CT. Of these, about 70,000 CT studies a month get processed by qure.ai’s algorithms. This collaboration has produced interesting insights into the challenges of implementing AI on such a large scale. Our earlier work together is published elsewhere at Imaging Wire and vRad’s blog.
Models that are accurate on extremely diverse data
Before we discuss the accuracy of models, we have to start with how we actually measure it at scale. In this respect, we have leveraged our experience from prior AI endeavors. vRad runs the imaging models during validation in parallel with production flows. As an imaging study is ingested into the PACS, it is sent directly to validation models for processing. In turn, as soon as the radiologist on the platform completes their report for the scan, we use it to establish the ground truth. We used our Natural Language Processing (NLP) algorithms to automatically read these reports to assign whether the current scan is positive or negative for ICH. Thus, the sensitivity and specificity of a model can be measured in real-time this way on real-world data.
AI models often perform well in the lab, but when tried in a real-world clinical workflow, it does not live up to expectations. This is a combination of problems. The idea of a diverse, heterogeneous cohort of patients is well discussed in the space of medical imaging. In this case, Qure.ai’s model was measured with a cohort of patients representative of the entire US population – with studies from all 50 states flowing through the model and being reported against.
Less commonly discussed are the challenges with the uniqueness of data that is a hospital or even imaging device-specific. vRad receives images from over 150,000 unique imaging devices in over 2,000 facilities. At a study level, different facilities can have many different study protocols – varying amounts of contrast, varying radiation dosages, varying slice thicknesses, and other considerations can change how well a human radiologist can evaluate a study, let alone the AI model.
Just like human radiologists, AI models do their best if they see consistent images at pixel level despite the data diversity. Nobody would want to recalibrate their decision process just because different manufacturers chose to use different post-processing techniques. For example, image characteristics of a thin slice CT scan are quite different from a 5mm thick scan with the former being considerably noisier. Both AI and doctors are sure to be confused if asked to decide whether those subtle hyperdense dots that they see on a thin slice scan are just noise or symptoms of diffuse axonal injury. Therefore, we invested considerably in making sure the diverse data is pre-processed into highly consistent raw pixel data. We discuss more in the following section.
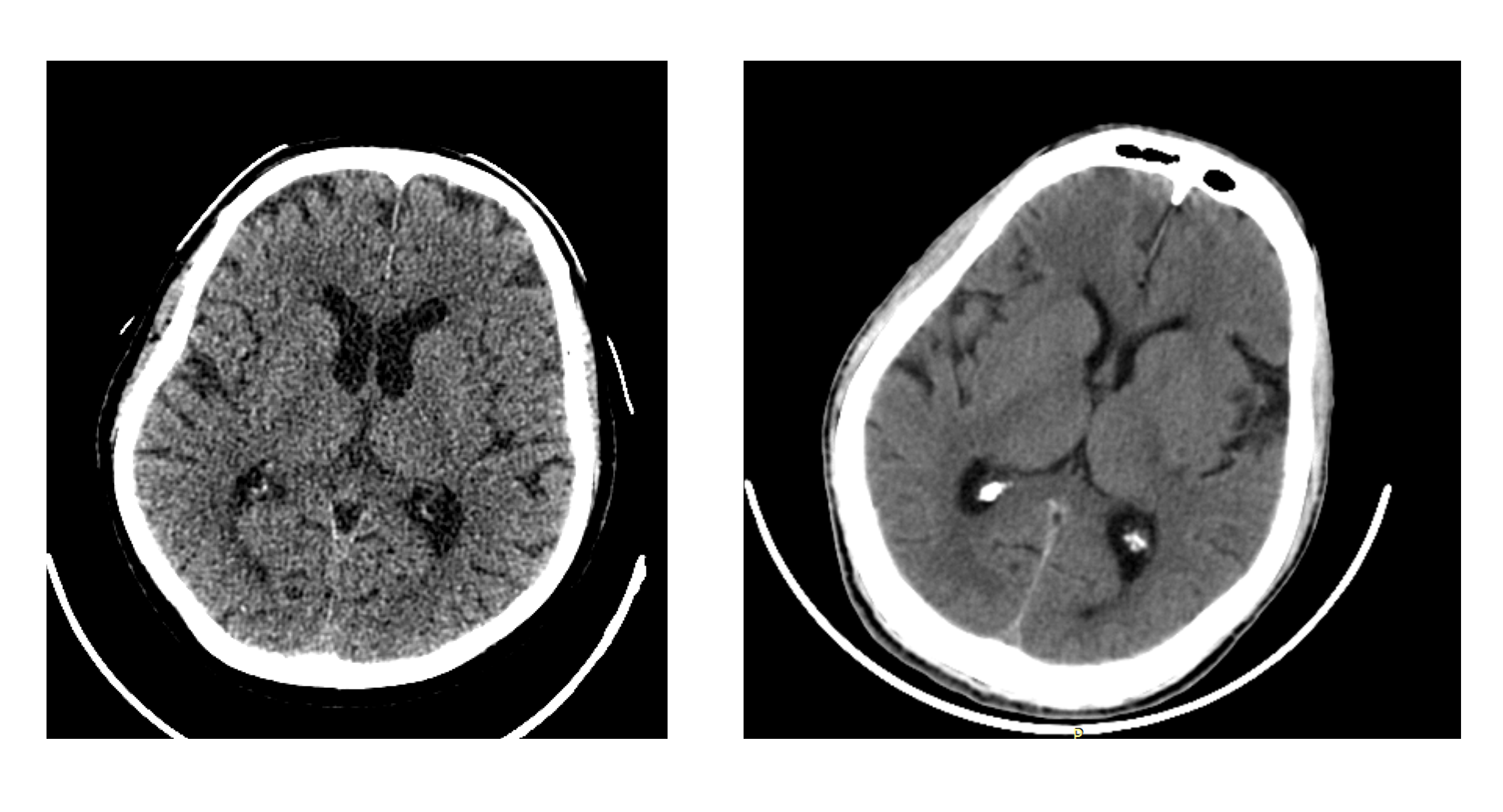
A thin slice CT (left) vs a thick slice one (right)
DICOM, AI, and interoperability
Dealing with patient and data diversity are major components of AI models. The AI model not only has to be generalizable at the pixel level, but it also must make sure the right pixels are fed into it. The first problem is highly documented in the AI literature but the second one, not so much. As traditional AI imaging models are trained to work on natural images (think cat photos), they deal with simplistic data formats like PNG or JPEG. However, medical imaging is highly structured and complex and contains orders more data compared to natural images. DICOM is the file format and standard used for storing and transfer the medical images.
While DICOM is a robust and well-adopted standard, implementation details vary. Often DICOM tags differ greatly from facility to facility, private tags vary from manufacturer to manufacturer, encodings and other imaging-device specific differences in DICOM require that any piece of software, including an AI model, be robust and good at error handling. After a decade of receiving DICOM from all over the U.S., the vRad PACS still runs into new unique configurations and implementations a few times a year, so we are uniquely sensitive to the challenges.

A taste of DICOM diversity: shown are random study descriptions used to represent CT brain
We realized that we need another machine learning model to solve this interoperability problem itself. How do we recognize that this particular CT image is not a brain image even if the description of images says so? How do we make sure the complete brain is present in the image before we decide there is a bleed in it? Variability of DICOM metadata doesn’t allow us to write simple rules which can work at scale. So, we have trained another AI model based on metadata and pixels which can make the above decisions for us.
These challenges harken back to classic healthcare interoperability problems. In a survey by Philips, the majority of younger healthcare professionals indicated that improved interoperability between software platforms and healthcare practices is important for their workplace satisfaction. Interestingly, these are the exact challenges medical imaging AI has to solve for it to work well. So, AI generalizability is just another name for healthcare interoperability. Given how we used machine learning and computer vision to solve the interoperability problems for our AI model, it might be that solving wider interoperability problems might involve AI itself.
AI Software Engineering
But even after those generalizability/interoperability challenges are overcome, a model must be hosted in some manner, often in a docker-based solution, frequently written in Python. And like the model, this wrapper must scale the solution. It must handle calls to the model and returning results, as well as logging information for the health of the system just like any other piece of software. As a model goes live on a platform like vRad’s, common problems that we see happen are memory overflows, underperforming throughput, and other “typical” software problems.
Although these problems look quite similar to traditional “software problems”, the root cause is quite different. For the scalability and the reliability of traditional software, the bottleneck usually boils down to database transactions. Take Slack, an enterprise messaging platform, for example. What’s the most compute-intensive thing Slack app does? It looks up the chat typed previously by your colleague from a database and shows it to you. Basically, a database transaction. The scalability of Slack usually means scalability and reliability of these database transactions. Given how databases have been around for years, this problem is fairly well solved with off-the-shelf solutions.
For an AI enabled software, the most compute intensive task is not a database transaction but running of an AI model. And this is arguably more intensive than a database lookup. Given how new deep learning is, the ecosystem around it is not yet well-developed. This make AI model deployment and engineering hard and it is being tackled by big names like Google (Tensorflow), Facebook (Torch), and Microsoft (ONNX). Because these are opensource, we actively contribute to them and make them better as we come across problems.
As different is the root cause of the engineering challenges, the process to tackle them is surprisingly similar. After all, engineers’ approach to building bridges and rockets is not all that different, they just require different tools. To make our AI scale to vRad, we followed traditional software engineering best practices including highly tested code and frequent updates. As soon as we identify an issue, we patch it up and write a regression test to make sure we never come across it again. Docker has made deployment and updates easy and consistent.

We get automated alerts of the errors and fix them proactively
Integration to clinical workflow
Another significant engineering challenge we solved is to bend clinical software to our will. DICOM is a messy communication standard and lacks some important features. For example, DICOM features no acknowledgement signal that the complete study has been sent over the network. Another great example is the lack of standardization in how a given study is described – what fields are used and what phrases are used to describe what the study represents. The work Qure.ai and vRad collaborated on the required intelligent mapping of study descriptions and modality information throughout the platform – from the vRad PACS through the Inference Engine running the models to the actual logic in the model containers themselves.
Many AI image models and solutions on the market today integrate with PACS and Worklists, but one unique aspect of Qure.AI and vRad’s work is the sheer scale of the undertaking. vRad’s PACS ingests millions of studies a year, around 1 billion individual images annually. The vRad platform, including the PACS, RIS, and AI Inference Engine, route those studies to the right AI models and the right radiologists, radiologists perform thousands of reads each night, and NLP helps them report and analyze those reports for continual feedback both to radiologists as well as AI models and monitoring. Qure.AI’s ICH model plugged into the platform and demonstrated robustness as well as impressive sensitivity and specificity.
During vRad and Qure.ai’s validation, we were able to run hundreds of thousands of studies in parallel with our production workloads, validating that the model and the solution for hosting the model was able to not only generalize for sensitivity and specificity but overcome all of these other technical challenges that are often issues in large-scale deployments of AI solutions.