ByteTrack: Multi-Object Tracking by Associating Every Detection Box
ByteTrack is a multi-object tracking algorithm. As of writing this blog, it is the SOTA on MOT17 and MOT20 datasets.
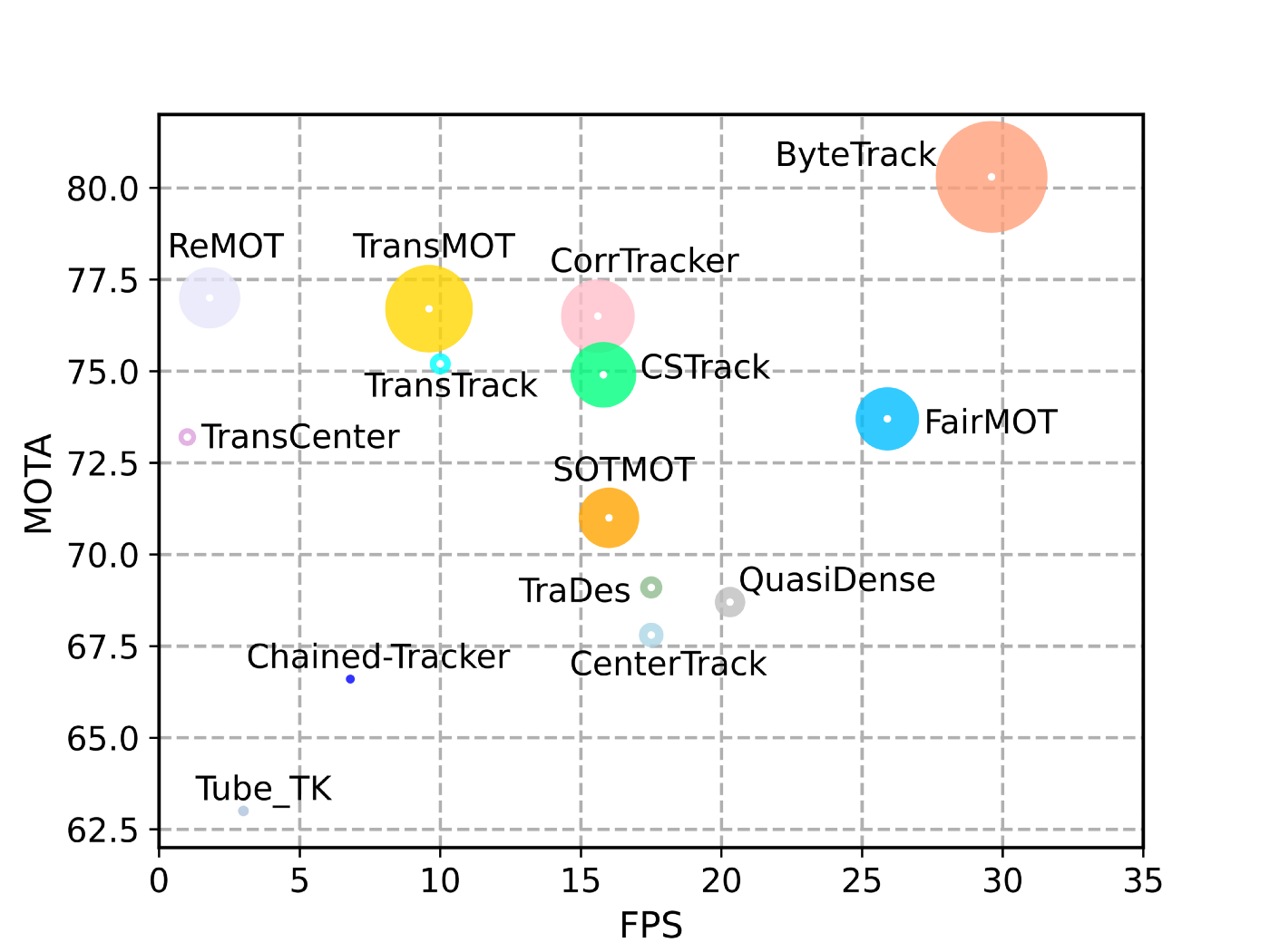 MOTA and FPS comparisons of different trackers (credits: ByteTrack paper)
MOTA and FPS comparisons of different trackers (credits: ByteTrack paper) To completely understand this paper we will divide this post into the following sections:
- Multi-Object Tracking (MOT)
- ByteTrack algorithm and implementation
- Results
Multi-Object Tracking
Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects in videos. A simple tracking algorithm can involve the following steps.
First, we detect the bounding boxes for all the objects (here we are only detecting persons in the image) in all the frames. In the image below, we have three frames and bounding boxes for all the persons highlighted in yellow, and the corresponding confidence threshold is mentioned at the top. Here we use an object detection algorithm to get the bounding box coordinates in all the frames.
 Detection across frames (image credits: ByteTrack paper).
Detection across frames (image credits: ByteTrack paper). Next, we use some algorithms like ByteTrack to associate these detection boxes across frames. In the image below, after applying the tracking algorithm we assign a tracking id to each object (persons). Here, objects with the same tracking ids are shown in the same color.
 BBox association result (image credit: ByteTrack paper).
BBox association result (image credit: ByteTrack paper). Note: There are variations in how different tracking algorithms work than what I have mentioned above. In general, any algorithm which does detection first and then uses that detection result to get tracking ids are called Tracking-by-detection. We will discuss some of those variations later.
I am not going into the details of detection. Let’s assume we are using one of the detection models(Yolov5, YoloX , RetinaNet and so on.) to get the bounding boxes from each frame. Note the official implementation of ByteTrack uses the YoloX model as object-detector.
Now for bounding box association, we can use two logic as follows:
1. IOU Trackers / Location-based trackers
Here, we assume that the video is captured at high FPS. So, between two consecutive frames, there is minimal movement of any objects. Now to associate objects across frames we can just calculate IoU (intersection over union) between detections of two consecutive frames. In the image above, the bounding boxes (they are shown in the same color across frames for the same object) of two objects are shown across frames.
Now if we calculate the IoU of detected bounding boxes, the same objects will have high overlap across frames than two different objects. In the above image, if we take any two consecutive frames the IoU for blue-blue or red-red boxes will be higher than for blue-red boxes. This way if two detected boxes have high IoU in two consecutive frames, we can give the same tracking id (in the image above, objects with the same tracking ids are in the same color).
Note: Detected boxes and bounding boxes are used interchangeably.
2. Feature-based trackers
Here instead of using location information (IoU), we use the features of the detected bounding boxes. We first find the bounding boxes in two frames. Then we calculate the features for each of the bounding boxes.
Then we can use cosine similarity to calculate the similarity of all the boxes from frame 1 to all the boxes from frame 2. We can give two detected boxes the same tracking id if they have a similarity value higher than a threshold and they don’t have any higher similarity matching with another bounding box.
Comparison of location-based and feature-based trackers
Location-based tracker fails when there is movement in-camera because then there might be high relative movement of an object across the frame the IoU value would be 0. In this case, the feature-based method will work because the relative position does not matter here.
If the detection algorithm has a low recall, then there will be objects which will be missed by the detector and if the detector fails for the same object continuously then when it will be detected again it might not have positive IoU with the last detected instance of this object in the previous frame.
Feature-based methods work fine with models with low recall. Here instead of checking one of the previous frames for matches, we can check some N numbers of the previous frames, so that even if the model does not detect an object in some of the frames when it detects the object again we have some old history to assign the same tracking id instead of a new one.
The feature-based method fails if there is very little distinction between two objects. For example, for tracking objects on a high-altitude thermal camera. Here every person will be a white blob (or black-blob based on the camera in white-hot mode or black hot mode) and will have a similar feature. The location-based method works fine here.
Location-based methods are also simple. We need to extract features for all the detected boxes and then calculate some similarity metrics for the feature-based method. Compared to that, in the location-based method, we can just calculate the IoU. A location-based method in general will be faster than a feature-based method.
Location-based methods take the assumption that cameras will have high FPS. Because most of the recent cameras have more than 30 FPS, it should not cause any issues.
ByteTrack
ByteTrack algorithm
ByteTrack is an IoU-based association algorithm. Most methods obtain identities by associating detection boxes whose scores are higher than a threshold. The objects with low detection scores, e.g. occluded objects, are simply thrown away, which brings non-negligible true object missing and fragmented trajectories. To solve this problem, ByteTrack uses both high and low-confidence bounding boxes.
Let’s understand the algorithm step by step:
Let’s assume a few things to understand the pseudo-code: The inputs are as follows: A video sequence V; object detector Det(this is YoloX); detection score threshold τ. The output would be: Tracks T of the video. In beginning, we will start with empty tracks.

For each frame in the video, we predict the detection boxes and scores using the YoloX detector. We separate all the detection boxes into two parts D_high and D_low according to the detection score threshold τ. For the detection boxes whose scores are higher than τ, we put them into the high score detection boxes D_high. For the detection boxes whose scores are lower than τ, we put them into the low score detection boxes D_low.

After separating the low score detection boxes and the high score detection boxes, we adopt the Kalman filter to predict the new locations in the current frame of each track in T.

The first association is performed between the high score detection boxes D_high and all the tracks T (including the lost tracks T_lost).

We keep the unmatched detections in D_remain and the unmatched tracks in T_remain. The second association is performed between the low score detection boxes D_low and the remaining tracks T_remain after the first association.

We keep the unmatched tracks in T_re−remain and just delete all the unmatched low score detection boxes, since we view them as background.
For the unmatched tracks T_re−remain after the second association, we put them into T_lost. For each track in T_lost, only when it exists for more than a certain number of frames (in paper, this value is 30 frames), we delete it from the tracks T . Otherwise, we remain the lost tracks T_lost in T
Finally, we initialize new tracks from the unmatched high score detection boxes D_remain after the first association.
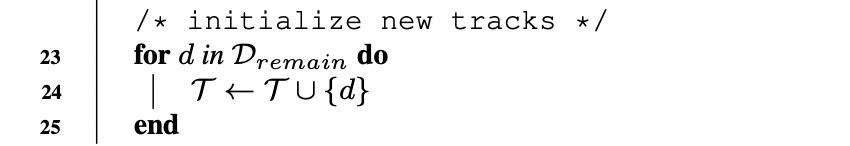
Note: for the association, we can use either location or feature-based method depending on the problem statement. The main addition of ByteTrack is of using both low and high-confidence bounding boxes.
ByteTrack implementation
Here lets check the important parts of the official implementation. Full implementation of ByteTrack code is here.
First, We initialize a few lists to keep tracking history:
tracked_stracks: tracks we are currently tracking and present in current frames.lost_stracks: tracks that we are currently tracking but missing in the current frame. Based onbuffer_size(saved inself.max_time_lost).removed_stracks: tracks that we have removed but tracked before.- We also initialize the kalman filter object to predict the location of the previously detected objects in the current frame. This along with high FPS with getting high IoU between the same object across frames.
class BYTETracker(object):
def __init__(self, args, frame_rate=30):
self.tracked_stracks = [] # type: list[STrack] # this is T
self.lost_stracks = [] # type: list[STrack] # this is T_lost
self.removed_stracks = [] # type: list[STrack] helps removing lost tracks if duration is finished
self.frame_id = 0 # current frame id
self.args = args
#self.det_thresh = args.track_thresh
self.det_thresh = args.track_thresh + 0.1
self.buffer_size = int(frame_rate / 30.0 * args.track_buffer) # how many frames to keep the lost frames
self.max_time_lost = self.buffer_size # buffer size
self.kalman_filter = KalmanFilter() # kalman filter, we will check this in details later
The update function takes care of associating tracks.
First, we rescale the bounding boxes to the original image size. Original image size information is saved into img_info variable and test image size is saved into img_size variable. We calculate the scale ratio and then rescale the bounding boxes to the original image size.
def update(self, output_results, img_info, img_size):
"""
Update function in bytetrack class
Args:
output_results: predictions fro object detection [N, x1,y1,x2,y2, score], [N, x1, y1, x2, y2, cls_conf, obj_conf]
img_info: original image size info
img_size: test image size info
"""
self.frame_id += 1
activated_starcks = []
refind_stracks = []
lost_stracks = []
removed_stracks = []
if output_results.shape[1] == 5: # [N, x1,y1,x2,y2, score]
scores = output_results[:, 4]
bboxes = output_results[:, :4]
else: # [N, x1, y1, x2, y2, cls_conf, obj_conf]
output_results = output_results.cpu().numpy()
scores = output_results[:, 4] * output_results[:, 5]
bboxes = output_results[:, :4] # x1y1x2y2
img_h, img_w = img_info[0], img_info[1]
scale = min(img_size[0] / float(img_h), img_size[1] / float(img_w))
bboxes /= scale # rescale bboxes back to original image size
Next, we separate bounding boxes into high confidence bounding boxes and low confidence bounding boxes. Here, we discard bounding boxes with less the 0.1 confidence. Low confidence bounding boxes have confidence between 0.1 and self.args.track_thresh. High confidence bounding boxes are boxes with confidence higher than self.args.track_thresh.
remain_inds = scores > self.args.track_thresh
inds_low = scores > 0.1
inds_high = scores < self.args.track_thresh
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second]
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
Next, we convert each detection into tracks. Then, we create a track pool by merging lost tracks with currently tracked tracks. We update track pool tracks with Kalman filter to get tracks with respect to the current frame.
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets, scores_keep)]
else:
detections = []
''' Add newly detected tracklets to tracked_stracks'''
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
''' Step 2: First association, with high score detection boxes'''
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# Predict the current location with KF
STrack.multi_predict(strack_pool)
Then we calculate the IoU distance between the track pool tracks and detection tracks and assign detections with tracks. We update the matched tracks with current detection boxes.
dists = matching.iou_distance(strack_pool, detections)
if not self.args.mot20:
dists = matching.fuse_score(dists, detections)
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh)
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
Similarly, we take low confidence bounding boxes and update the tracks (only the tracks which were not matched during the first association) with detection information from the current frame.
''' Step 3: Second association, with low score detection boxes'''
# association the untrack to the low score detections
if len(dets_second) > 0:
'''Detections'''
detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets_second, scores_second)]
else:
detections_second = []
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
dists = matching.iou_distance(r_tracked_stracks, detections_second)
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
The remaining unmatched tracks will be added to the lost track list.
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
For unmatched high detection boxes, if the detection confidence is higher than det_thresh then we add them as new tracks.
""" Step 4: Init new stracks"""
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
For all the tracks in the lost track list, if time is higher than max_time_lost then we discard those tracks.
""" Step 5: Update state"""
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
Results
ByteTrack outperforms other tracking menthods on MOT17, MOT20 and HiEve test dataset by a large margin.
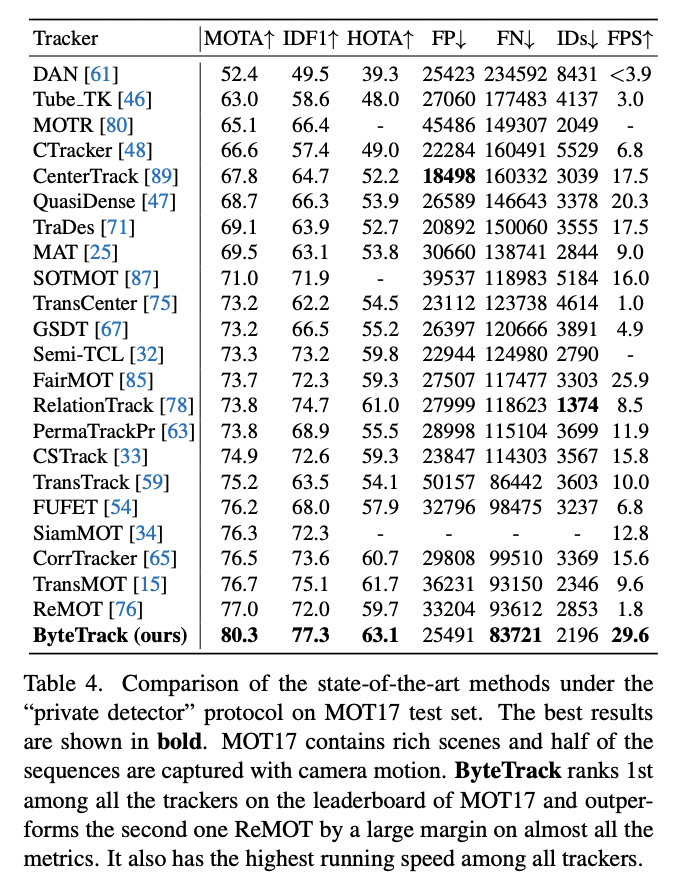 ByteTrack performance on MOT17 testset (Source: ByteTrack paper)
ByteTrack performance on MOT17 testset (Source: ByteTrack paper) 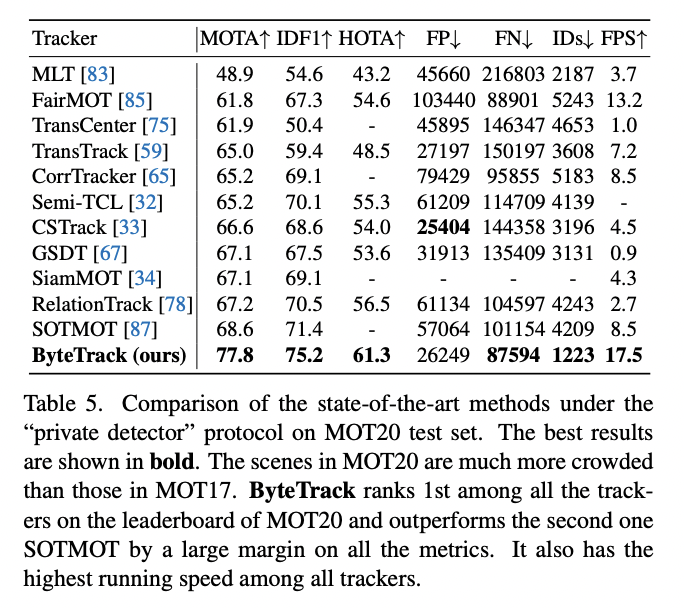 ByteTrack performance on MOT20 dataset (Source: ByteTrack paper)
ByteTrack performance on MOT20 dataset (Source: ByteTrack paper) 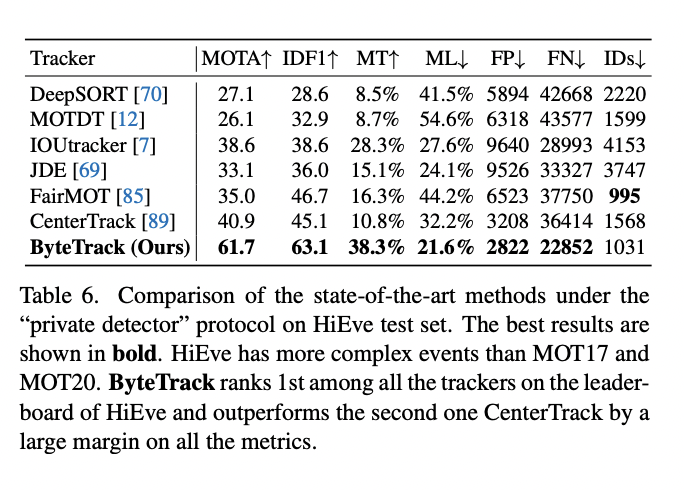 ByteTrack performance on HiEve testset (Source: ByteTrack paper)
ByteTrack performance on HiEve testset (Source: ByteTrack paper) Note: There are many benchmark tests done by the authors of the paper and details are in the paper.
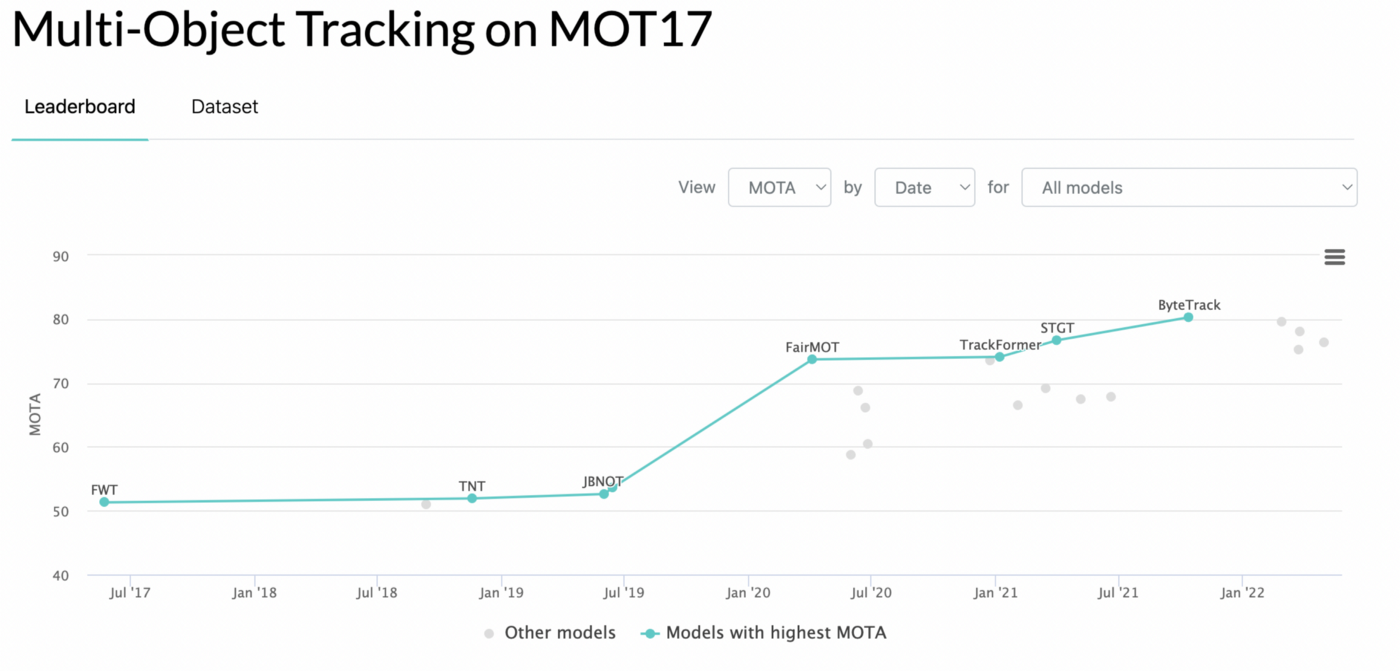
SOTA methods on MOT17 in papers with code
Hope you enjoyed this paper. Have a nice day.