What We Learned Deploying Deep Learning at Scale for Radiology Images
Qure.ai is deploying deep learning for radiology across the globe. This blog is the first in the series where we will talk about our learnings from deploying deep learning solutions at radiology centers. We will cover the technical aspects of the challenges and solutions in here. The operational hurdles will be covered in the next part of this series.
The dawn of an AI revolution is upon us. Deep learning or deep neural networks have crawled into our daily lives transforming how we type, write emails, search for photos etc. It is revolutionizing major fields like healthcare, banking, driving etc. At Qure.ai, we have been working for the past couple of years on our mission of making healthcare more affordable and accessible through the power of deep learning.
Since our journey began more than two years ago, we have seen excellent progress in development and visualization of deep learning models. With Nvidia leading the advancements in GPUs and the release of Pytorch, Tensorflow, MXNet etc leading the war on deep learning frameworks, training deep learning models has become faster and easier than ever.
However, deploying these deep learning models at scale has become a different beast altogether. Let’s discuss some of the major problems that Qure.ai has tackled/is tackling in deploying deep learning for hospitals and radiologists across the globe.
Where does the challenge lie?
Let us start with understanding how the challenges in deploying deep learning models are different from training them. During training, the focus is mainly on the accuracy of predictions, while deployment focuses on speed and reliability of predictions. Models can be trained on local servers, but in deployment, they need to be capable of scaling up or down depending upon the volume of API requests. Companies like Algorithmia and EnvoyAI are trying to solve this problem by providing a layer over AI to serve the end users. We are already working with EnvoyAI to explore this route of deploying deep learning.
Selecting the right deep learning framework
Caffe was the first framework built to focus on production. Initially, our research team was using both Torch (flexible, imperative) as well as Lasagne/Keras (python!) for training. The release of Pytorch in late 2016 settled the debate on frameworks within our team.

Deep learning frameworks (source)
Thankfully, this happened before we started looking into deployment. Once we finalized Pytorch for training and tweaking our models, we started looking into best practices for deploying the same. Meanwhile, Facebook released Caffe2 for easier deployment, especially into mobile devices.
The AI community including Facebook, Microsoft and Amazon came together to release Open Neural Network Exchange (ONNX) making it easier to switch between tools as per need. For example, it enables you to train your model in Pytorch and then export it into Caffe2/ MXNet/ CNTK (Cognitive Toolkit) for deployment. This approach is worth looking into when the load on our servers increase. But for our present needs, deploying models in Pytorch has sufficed.
Selecting the right stack
We use following components to build our Linux servers keeping our pythonic deep learning framework in mind.
Docker: For operating system level virtualization
Anaconda: For creating python3 virtual environments and supervising package installations
Django: For building and serving RESTful APIs
Pytorch: As deep learning framework
Nginx: As webserver and load balancer
uWSGI: For serving multiple requests at a time
Celery: As distributed task queue
Most of these tools can be replaced as per requirements. The following diagram represents our present stack.
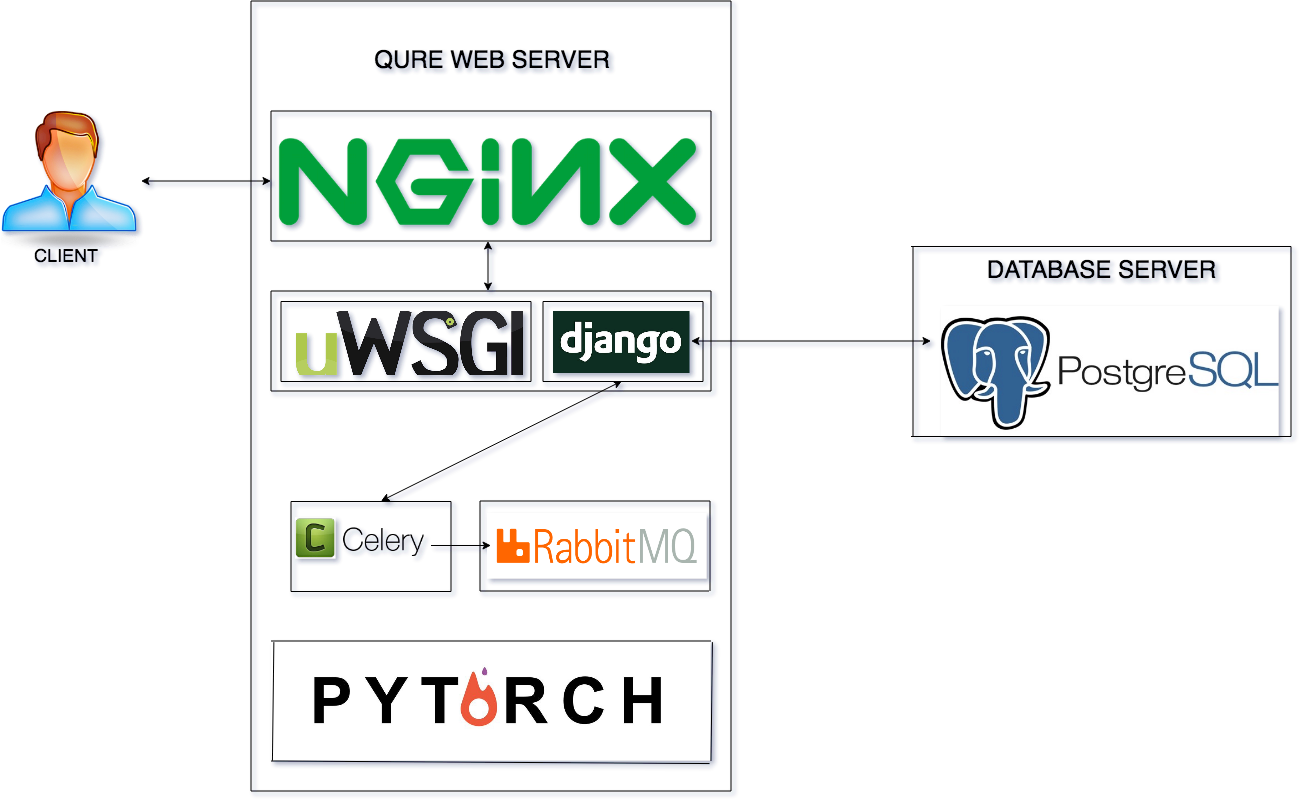
Server architecture
Choosing the cloud GPU server
We use Amazon EC2 P2 instances as our cloud GPU servers primarily due to our team’s familiarity with AWS. Although, Microsoft’s Azure and Google Cloud can also be excellent options.
Automating scaling and load balancing
Our servers are built using small components performing specific services and it was important to have them on the same host for easy configuration. Moreover, we handle large dicom images (each having a size between 10 and 50 Mb) and they get transferred between the components. It made sense to have all the components on the same host or else, the network bandwidth might get choked due to these transfers. The following diagram illustrates various software components comprising a typical qure deployment.
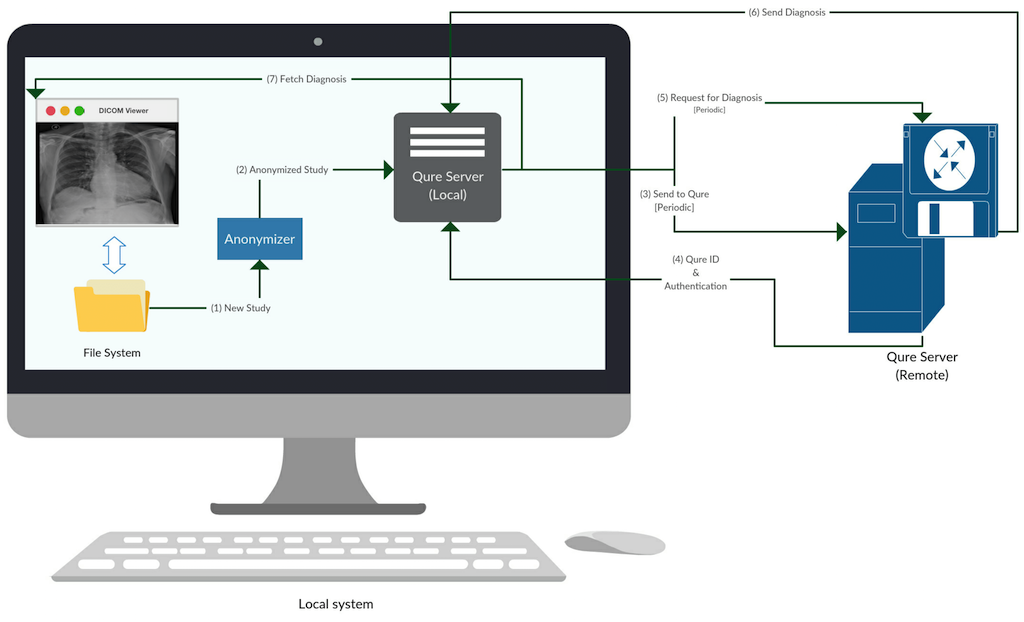
Software Components
We started with launching qXR (Chest X-ray product) on a P2 instance but as the load on our servers rose, managing GPU memory became an overhead. We were also planning to launch qER (HeadCT product) which had even higher GPU memory requirements.
Initially, we started with buying new P2 instances. Optimizing their usage and making sure that few instances are not bogged down by the incoming load while other instances remain comparatively free became a challenge. It became clear that we needed auto-scaling for our containers.
Load balancing improves the distribution of workloads across instances (source)
That was when we started looking into solutions for managing our containerized applications. We decided to go ahead with Kubernetes (Amazon ECS is also an excellent alternative) majorly because it runs independently of specific provider (ECS has to be deployed on Amazon cloud). Since many hospitals and radiology centers prefer on-premise deployment, Kubernetes is clearly more suited for such needs. It makes life easier by automatic bin-packing of containers based on resource requirements, simpler horizontal scaling, and load balancing.
GPU memory management
Initially, when qXR was deployed, it dealt with fewer abnormalities. So for an incoming request, loading models into memory, processing images through it and then releasing the memory worked fine. But as the number of abnormalities (thereby models) increased, loading all models sequentially for each upcoming request became an overhead.
We thought of accumulating incoming requests and processing images in batches on a periodic basis. This could have been a decent solution except that time was critical when dealing with medical images, more so in emergency situations. It was especially critical for qER where in cases of strokes, one has less than an hour to make a diagnostic decision. This ruled out the batch processing approach.

Beware of GPUs !! (warning at Qure's Mumbai office)
Moreover, our models for qER were even larger and required approximately 10x GPU memory of what qXR models required. Another thought was to keep the models loaded in memory and process images through them as the requests arrive. This is a good solution where you need to run your models every second or even millisecond (think of AI models running on millions of images being uploaded to Facebook or Google Photos). However, this is not a typical scenario within the medical domain. Radiology centers do not encounter patients at that scale. Even if the servers send back the results within a couple of minutes, that’s like a 30x improvement in the amount of time that a radiologist would take to report the scan. And that’s when you assume that a radiologist is immediately available. Otherwise, an average turnaround period of a chest x-ray scan varies from 1 to 2 days (700-1400x of what we take currently).
As of now, auto-scaling with Kubernetes solves our problems but we would definitely look into it in future. The solution lies somewhere between the two approaches (think of a caching mechanism for deep learning models).
Conclusion
Training deep learning models, especially in healthcare, is only one part of building a successful AI product. Bringing it to healthcare practitioners is a formidable and interesting challenge in itself. There are other operational hurdles like convincing doctors to embrace AI, offline working style at some hospitals (using radiographic films), lack of modern infrastructure at radiology centers (operating systems, bandwidth, RAM, disk space, GPU), varying procedures for scan acquisition etc. We will talk about them in detail in the next part of this series.
Note
For a free trial of qXR and qER, please visit us at scan.qure.ai